
Mamy już wiosnę, a to znaczy, że czas na porządki i to nie tylko w domu, ale również w… Google. Tak, tak – dzisiaj posprzątamy wyniki wyszukiwania ze zbędnych podstron, które zostały niepotrzebnie zaindeksowane. Działania takie należy przeprowadzić zwłaszcza na początku prac nad stroną, aby wyeliminować każdy element, który może mieć negatywny wpływ na widoczność witryny.
Dlaczego tak ważne jest, aby zrobić porządki w Google?
Wyszukiwarki lubią mieć w swoim indeksie tylko wyniki unikalne, zróżnicowane i zarazem o wysokiej jakości. Również w naszym interesie jest, aby ich roboty poświęciły cały czas spędzony na naszej stronie na odświeżaniu kopii najważniejszych podstron i indeksowaniu struktury, ale tylko tej, na którą chcemy skierować ruch organiczny.
W związku z powyższym Google rekomenduje, aby nie indeksować m.in. wyników wyszukiwania ani filtrowania, ponieważ nie wnoszą one dodatkowej wartości poza inną prezentacją tych samych treści – mamy wtedy do czynienia z tzw. duplicate content. Jeśli nawet je zaindeksuje, nie oceni ich wysoko, a zatem sztuczne nabijanie liczby podstron w niczym nam nie pomoże. Co więcej, duża liczba zaindeksowanych podstron o niskiej jakości (to tzw. thin content) może negatywnie wpłynąć na ocenę i widoczność całej strony.
Powinniśmy więc zadbać o porządek w Google, dlatego zaczniemy od zabawy w SEO detektywa i poszukamy podstron, które nie powinny być indeksowane.
Jak szukać podstron do wyindeksowania
Zacznijmy od sprawdzenia struktury strony WWW i wskazania charakterystycznych fragmentów URL, które występują w adresach podstron niechcianych w indeksie Google. W celu weryfikacji stanu indeksu analizowanej witryny skorzystamy z podstawowej komendy każdego seowca, tj. site i połączymy je z innymi operatorami Google. Zazwyczaj ogólna komenda pokazuje mniej dokładne dane niż ta bardziej doprecyzowana.
Oto kilka przykładów:
- site:lexy.com.pl – zwraca liczbę zaindeksowanych podstron w ramach mojej domeny i wynosi ona 577;
- site:lexy.com.pl/blog/ – jw., tyle że zwróci wyniki dla samego bloga, których powinno być o 1 podstronę mniej niż w pierwszym zapytaniu; jak już wspomniałam, ogólne zapytanie pokazuje mniej danych, co widać na tym przykładzie, który zwrócił 730 podstron;
- site:lexy.com.pl inurl:blog – to zapytanie teoretycznie powinno zwrócić te same wyniki, co wyżej, jednak liczby te nieco się od siebie różnią;
- site:lexy.com.pl inurl:add-to-cart – tutaj już wchodzimy w zapytania o formaty adresów specyficzne dla opcji, które nie powinny być indeksowane; na tym przykładzie są to podstrony dodania do koszyka wybranego produktu w sklepie, których nie potrzebujemy w indeksie Google;
- site:lexy.com.pl filetype:html – pokaże wyniki zawężone do tych, których rozszerzenie to .html, a zatem na przykładzie mojej strony będą to wszystkie wpisy na blogu; warto posprawdzać w ten sposób, czy nie zaindeksowały się żadne pliki pdf, docx czy xls;
- site:lexy.com.pl -filetype:html – to z kolei przeciwieństwo poprzedniego przykładu, ponieważ ze zwróconych wyników wykluczamy te o rozszerzeniu .html;
- site:lexy.com.pl/blog/ inurl:/wp-content/ – w ten sposób możemy sprawdzić zaindeksowane pliki, w tym te dotyczące wtyczek na blogu.
Początkowo, kiedy potrzebujemy ogólnej orientacji w tym, co znajduje się w SERPach, wystarczy ogólne zapytanie o site dla danej domeny. Doprecyzowujemy je dopiero dla problematycznych podstron, aby wyciągnąć ich pełniejszą listę. Nie powinno nas dziwić, że Google co jakiś czas wyświetli nam CAPTCHĘ w ramach zabezpieczeń przed nietypowymi zapytaniami.
Najlepiej od razu przescrollować wyniki na sam dół i zobaczyć, co kryje się na ich końcu, zwłaszcza pod linkiem informującym o ukryciu wyników uzupełniających. To tam najczęściej trafiają podstrony, które będziemy chcieli wyindeksować.
Aby pokazać najbardziej trafne wyniki, pominęliśmy kilka pozycji bardzo podobnych do 63 już wyświetlonych.
Jeśli chcesz, możesz powtórzyć wyszukiwanie z uwzględnieniem pominiętych wyników.
Takie poszukiwania mogą doprowadzić nas do następujących wyników:
- różne wersje adresów, tj. z WWW i bez WWW, z HTTP i HTTPS – sprawdzimy je po wpisaniu zapytań w postaci:
- site:www.lexy.com.pl – zaindeksowane adresy z WWW;
- site:lexy.com.pl -inurl:www lub site:domena.pl -site:www.lexy.com.pl – adresy z wykluczeniem tych z WWW;
- site:lexy.com.pl inurl:http – adresy z HTTP; efektu tego nie uzyskamy zapytaniem site:http://www.lexy.com.pl;
- site:lexy.com.pl inurl:https lub site:lexy.com.pl -inurl:http – adresy z HTTPS;
- subdomeny niespodzianki – za pomocą komendy site:lexy.com.pl -site:www.lexy.com.pl sprawdzimy zaindeksowane subdomeny. Może się okazać, że znajdziemy tam robocze adresy URL, tj. subdomeny wykorzystywane pod roboczą wersję strony, czy też dodatkowe sklepy, blogi i inne strony, o których powinniśmy zostać poinformowani już na początku współpracy. Pamiętajmy, że grzeszki subdomeny mogą się odbić na kondycji wszystkich serwisów w ramach domeny, dlatego zwłaszcza podczas analizy spadków pozycji należy zwrócić uwagę na to, która z subdomen zawiniła;
- wyniki wyszukiwania – trzeba sprawdzić, jaki format adresu mają wyniki wyszukiwania na stronie, aby wiedzieć, co wyszukać w Google. Pamiętajmy, że wyszukiwarka ignoruje znaki „?”, które często wyświetlają się w adresie strony tuż przed wskazaniem wyszukiwanej frazy, dlatego też w komendach w Google trzeba się posługiwać fragmentami adresów z wykluczeniem ignorowanych znaków, np. dopisując inurl:search lub inurl:query;
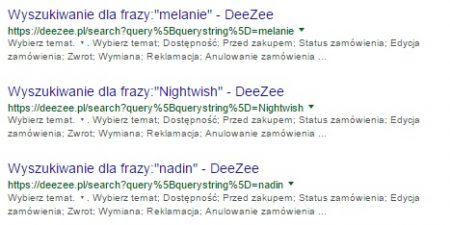
- wyniki sortowania – w przypadku strony sklepu najczęściej wystarczy dopisanie inurl:sort, który wskaże na wyszukiwanie adresów URL z parametrem odpowiedzialnym za sortowanie wyników;
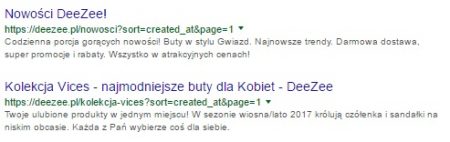
- wyniki filtrowania;
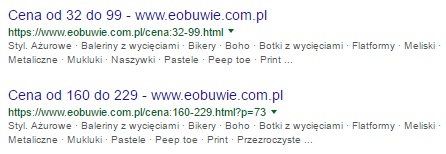
- stara struktura adresów URL;
- podstrony wygenerowane automatycznie – tu ciężko wskazać konkretne zapytanie, ponieważ każdy przypadek będzie indywidualny; chodzi m.in. o podstrony wygenerowane przez wykorzystanie dziur w skryptach, które nawet po usunięciu błędu pozostaną na długo w indeksie i będą zwracać nagłówek 404;
- adresy URL komentarzy – do standardowej komendy dopisujemy np. inurl:fb_comment_id;
- adresy otagowanych linków – w tym przypadku dopiszemy np. inurl:utm_source;
- adresy zawierające #! – dopiszemy wtedy inurl:_escaped_fragment;
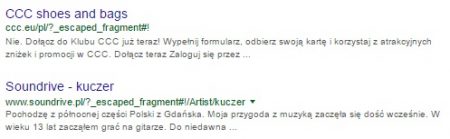
- inne – np. wersje do druku, wersje PDF opublikowanych artykułów, adresy z identyfikatorami sesji.
Jak wyindeksować niechciane podstrony z Google?
Jak już pisałam, Google nie chce w swoim indeksie duplikatów, a te właśnie tworzą się, jeśli ta sama zawartość jest dostępna pod różnymi adresami, np. adres z WWW, bez WWW itp. Problem dotyczy zarówno kopii 1:1, jak i sytuacji, w których duża część informacji pod jednym adresem pokrywa się z tymi dostępnymi na innych adresach, czyli np. w wynikach wyszukiwania czy innego rodzaju filtrowania bądź zawężania prezentowanych informacji. To nie tylko zwiększa ryzyko tego, że Google słabo oceni cały serwis, traktując dużą część podstron jako duplicate content czy też thin content, ale także powoduje problem z kanibalizacją słów kluczowych. Dochodzi do niej, kiedy wyszukiwarka nie jest pewna co do tego, który spośród kilku adresów jest bardziej trafnym wynikiem dla wyszukanej frazy – np. podstronę kategorii czy taga na blogu.
Mamy kilka możliwości w zakresie kontrolowania tego, co znajduje się w indeksie. Jeśli nie chcemy w nim części podstron, do dyspozycji mamy następujące rozwiązania:
- ustawienie przekierowania 301 lub użycie rel=”canonical” na docelowy adres – obydwa rozwiązania powinny skutkować przeniesieniem na preferowany przez nas adres mocy płynącej z linków. Główna różnica polega na tym, że 301 działa również na użytkowników, przekierowując ich na inny adres URL, podczas gdy canonicala nie zauważy przeciętny internauta;
- ręczne zgłoszenie w Google Search Console – chodzi o opcję dostępną w zakładce Indeksowanie ⇒ Usunięcia. Można w ten sposób wyindeksować pojedynczy adres, a nawet cały folder za jednym zamachem. Teoretycznie, w przypadku braku zastosowania blokady dostępu do zgłaszanych podstron lub metatagu noindex (lub none, czyli noindex + nofollow), takie podstrony mogą wrócić do indeksu po upłynięciu 6 miesięcy od zgłoszenia;
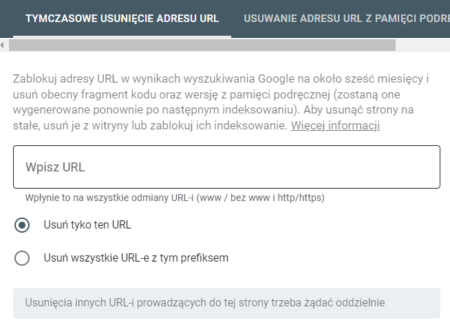
źródło: Google Search Console – zgłoszenie usunięcia
- blokada dostępu ustawiona w pliku robots.txt – rozwiązanie to nie zabezpieczy jednak przed indeksacją adresu. Jego celem jest zablokowanie dostępu robota przed wejściem na daną podstronę, pobraniem jej kopii i wyświetleniem w wynikach wyszukiwania jej wyniku z zajawką pobraną z zawartości strony. Mimo wszystko dla struktury takiej jak wyniki wyszukiwania lub sortowania warto z niej skorzystać. Dzięki takiej blokadzie roboty wyszukiwarek skupią się na skanowaniu głównej struktury witryny zamiast tej, która nie prezentuje unikalnej zawartości. Niestety nie da się jednocześnie zablokować robotom dostępu do wybranych sekcji strony i zapobiec ich wyświetlaniu w SERP-ie. Po szczegóły na ten temat odsyłam do mojego wpisu na blogu SeoStation: Co pierwsze: robots.txt czy META);
- stosowanie nofollow – chodzi o w użycie nofollow w linkach do podstron, których roboty wyszukiwarek nie powinny odwiedzać. Oznaczenie takie dosłownie oznacza: nie podążaj. Skorzystanie z tego rozwiązania nie gwarantuje jednak tego, że strona nie trafi do indeksu, zwłaszcza jeśli już się w nim znalazła. Niestety nie jest to rozwiązanie w 100% pewne, ponieważ w 2019 r. Google zmieniło podejście do nofollow i od tej pory zastrzega, że w niektórych przypadkach może podążyć za takimi linkami. Więcej na ten temat opisałam we wpisie: Historia linków nofollow, ugc i sponsored;
- fizyczne usunięcie podstron – jeśli konieczne jest całkowite pozbycie się części podstron, należy zwrócić uwagę na to, aby ustawić odpowiedni status, tj. 404 albo 410, a nie przypadkiem 200 z wyświetlonym komunikacie o braku wyniku – to tzw. miękkie (czy też pozorne) 404. Warto zweryfikować to uruchamiając z poziomu przeglądarki narzędzia dla dewelopera – w Google Chrome można skorzystać w tym celu ze skrótu Ctrl + Shift + I albo wejść w ustawienia w zakładkę Więcej narzędzi ⇒ Narzędzia dla dewelopera.
Zadanie praktyczne
Teraz Ty wciel się w rolę detektywa.
Wejdź na swoją stronę i dokładnie sprawdź jej strukturę. Czy ma opcje filtrowania, sortowania albo wyszukiwania? Spisz charakterystyczne dla nich fragmenty adresów URL i przeszukaj Google w poszukiwaniu podstron, które powinieneś… posprzątać.
Zdecyduj, jaki sposób będzie najlepszy, aby z jednej strony usunąć niechciane wyniki wyszukiwania, a z drugiej – zabezpieczyć się przed ich indeksacją na przyszłość. Podziel się efektami w komentarzu do tego wpisu.
PS Ten wpis został opublikowany w 2017 r. i zaktualizowany w 2023 r., aby rozwinąć temat i zapewnić zgodność informacji ze stanem aktualnym. Aby nie przegapić kolejnych, śledź mój FanPage.